
Uncovering our values, with a dash of spirituality
2018-08-28
At Skyscrapers we’ve standardized on Concourse for our CICD system, both for ourselves and for our customers. It is an integral part of our latest Kubernetes & AWS ECS Reference Solutions. As we’ve recently open-sourced the terraform-concourse module, we figured it would be a good moment to explain how we choose to implement Concourse, pointing out some challenges we had en-route.
Concourse is a next generation continuous integration and delivery tool. Similar to configuration management tools, the full setup is described as code and put under source control. This is a major improvement over other CI systems and setups that are often difficult to reproduce in case of failure.
As with everything else we deploy we setup Concourse with our own Terraform module. We are open sourcing it so other people and companies can benefit from it and can help us improve it. You can find it in Github.
Here are some of the design choices of our Concourse setup and the reasons why we chose them.
At Skyscrapers containerized environments and container platforms, such as Kubernetes and AWS ECS, are major parts of the solutions we offer. With that in mind we deploy most of our tooling, and various supporting applications on a dedicated ECS cluster, separate from the ECS or Kubernetes running the customer workloads.
We tried running the Concourse workers on the same ECS cluster, but we quickly hit some performance problems. Concourse itself can be considered a container scheduler, as all the jobs and tasks in Concourse run as containers inside the worker nodes, scheduled by the web component. So we were essentially running containers inside containers, which wasn’t very efficient. We then decided to run the worker nodes as standalone EC2 instances.
There’s a draft proposal from Concourse to implement a Kubernetes runtime in Concourse. Instead of scheduling the task containers in worker nodes it would be able to schedule them directly as Pods in a Kubernetes cluster. You can find this proposal in the Concourse RFCs repository in GitHub.
Concourse workers register themselves to the TSA, providing a trusted RSA key for authorization. The idea of our Concourse setup is to have a dynamic worker pool based on the premise that workers can come and go without manual intervention. That’s why we needed a practical and secure way to distribute the trusted worker RSA key(s). We chose to use an S3 bucket for that purpose.
The keys Terraform module will create the S3 bucket (with server-side-encryption enabled), generate three RSA key-pairs via the Terraform local-exec provisioner and upload them to S3. The IAM policies of both the worker EC2 instances and the web ECS task will be granted read access to that bucket. When the web container boots up it pulls the needed keys from S3 and uses the workers public key as a trusted key for worker registration. At the same time, when the workers boot up they also pull the keys from S3 and use the private key to register with the TSA.
I’m sure this specific part of the setup can be greatly improved in terms of security, so any input and feedback is welcomed.
Here’s more info on how the previously-mentioned RSA keys are generated and how they’re used: https://concourse-ci.org/install.html#generating-keys
Concourse needs three external ports 80, 443 and 2222 to be reachable and routed to the web container. The first two are the http and https ports for the Web UI, and the last one is a TCP port needed for workers to register to the TSA.
Due to that port combo we can’t use a single ALB for all of them. An ALB is a layer 7 balancer that doesn’t support plain TCP listeners. Instead we would need an ALB for the http(s) ports and an NLB for the 2222 port which would increase cost and complexity of the overall setup. That’s why we decided to go with a classic ELB instead so we can use the same load balancer for all ports. The downside of using an ELB is that it doesn’t integrate as well with ECS and we assume that it’s going to be deprecated and removed eventually.
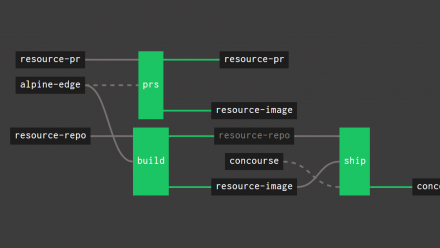
The best representation of the actual setup can be found in the module’s documentation, but in any case I’ll try to summarize it here.
Our Concourse deployment is composed of two parts, web and the workers. web is a container that runs on an AWS ECS cluster. It combines both the ATC and TSA, which are two Concourse components. The workers are standalone EC2 instances that register with the TSA. They and are responsible for running the actual workloads deployed by Concourse.
The web part is being deployed by the ecs-web Terraform module, together with an ELB that will handle all of the traffic towards the ECS service.
The workers are being deployed by the ec2-worker Terraform module which creates an autoscaling group to make it easy to adjust the size of the worker fleet. To increase the jobs performance in Concourse, the workers have a large, high reserved IOPS external EBS volume attached to them.
You’ll also see a couple more Terraform modules in the GitHub repository, keys and vault-auth. keys is responsible for creating the S3 bucket where the RSA keys for worker registration will be stored. Using this both web and workers can access the keys from that bucket and workers can authenticate securely with the TSA.
Finally the vault-auth module is needed when you want to integrate Concourse with HashiCorp Vault. It is highly recommended to do so when you have sensitive information in your pipeline definitions.
There are some resources that are needed for this Concourse setup that aren’t covered by the previously mentioned modules:
web container. We also have Terraform ECS related modules for that: https://github.com/skyscrapers/terraform-ecsThese are some of the topics that we would like to improve in the near future of our Concourse setup.
This is not a specific limitation of our setup, but of the actual Concourse implementation of Vault. But I think it’s worth mentioning in any case.
There are a couple of limitations with the current way Concourse is integrated with Vault:
The Vault integration is still useful to store static secrets like passwords, tokens or Git keys instead of putting them in a plain secrets.yaml file which is quite hard to distribute to the team. But you have to be aware that for the moment this integration won’t allow you to dynamically provision AWS credentials for example.
On the bright side it’s good to know that there’s work being done to improve the credential manager support in Concourse, including the Vault integration. You can find more information in the Concourse RFCs repository in GitHub.
Our next two big things to tackle for our Concourse setup are a self-update ability and monitoring. I think self-update is going to be handled by an actual pipeline in the same Concourse setup. We’re considering using Grafana and Prometheus (already used in other areas of our Reference Solutions) for monitoring and alerting. So stay tuned for future updates.
The current setup is open for improvement, so all ideas, feedback and improvements you can provide are very welcomed. You can either use GitHub issues or drop us a PR. In the meantime, we hope you find the Terraform modules useful.
And remember, don’t want to figure it all out yourself? We can help!







Need a solid go-to partner to discuss your DevOps strategy?