
Uncovering our values, with a dash of spirituality
In this story we tell you how we evolved a classic, high traffic, monolithic application to a serverless architecture using AWS Lambda, DynamoDB and Kinesis. The result is a highly reliable, scalable and cost effective (91% saved on AWS costs) application.
For a long-time customer we regularly set up short-lived AWS environments. These hosted their national interactive campaigns with a high level of exposure and a lot of visitors in very short times. The configuration we setup every time was stable but outdated. With newer technology available there was an opportunity to improve the platform.

The platform was based on EC2 instances in an autoscaling group backed by a beefy RDS MySQL database. With recent changes to the application, the database became more and more of a bottleneck for the environment and thus we needed to scale it up which resulted in a higher AWS bill.
We weren’t happy working this way and proposed to do a brainstorming session with the customer to improve the platform. During this session with the customer we quickly concluded that we both wanted to step away from classic infrastructure and that this would involve having to start coding from scratch. The idea was to transform the classic monolithic PHP setup to a fully serverless architecture.
We needed a platform that would scale almost instantly from handling 0 to 50k requests per minute and more. Normal autoscaling can’t handle this so we needed to think outside the box.
By using serverless components from AWS we quickly realised that these are perfect for this use case. You only pay for the runtime that is actually used and you don’t have any idle costs of running extra capacity when it’s not needed.
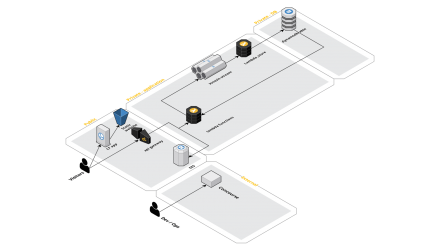
The old platform ran on RDS and it had been a bottleneck. We took a look at the data that was stored and concluded that a nosql database was best suited. We selected DynamoDB on demand that was recently announced because that would allow only paying for what we consume and we would not have to over-provision the tables to handle the peaks in traffic.
Decoupling as much as possible is key in serverless environments and therefore we applied one of the well architected patterns of AWS by adding Kinesis in between the Lambda functions behind the API Gateway and the database. By doing this we would have a buffer if something goes wrong in the database layer. On top of that Kinesis offers the functionality of saving the records that are going through it for a defined time. This increases the reliability of the data.

After making the initial design we needed to validate if the newly designed platform could handle the load that was estimated, up to and beyond 50k requests / minute.
When the base api functionality was developed we were ready to put things to the test. It became clear that Lambda was not going to be a bottleneck. However the load test showed that when the concurrency of the load test increased the time it took for the records to go from Kinesis to Dynamodb increased significantly.
This needed to be fixed before we continued…
Kinesis had no trouble capturing all the data. However the bottleneck was the Lambda function, that was triggered by Kinesis, responsible for pushing the data to DynamoDB. After tweaking the batch size of the chunks that were processed per Lambda function we didn’t notice any significant improvement.
After digging around in the documentation of Kinesis we found out we were hitting the read limit of Kinesis (5 per second per shard). There were 2 options: we could increase the shards, which would increase the events to Lambda and thus increase the amount of Lambda functions that ran in parallel. Option 2 was to enable the Enhanced Fan-Out feature of Kinesis; this would improve the read parallelism per shard by providing each consumer with its own throughput limit.
We opted to increase the number of shards and confirmed with load testing that with 6 shards and batch sizes of 300 from Kinesis to the Lambda function we could meet the required capacity for the projects. We also confirmed that the platform could handle a LOT more by increasing the shards in Kinesis.
From the start the customer opted to code the backend in Node.Js. By limiting the code size and functionally per Lambda function we could run all functions at minimal specs and thus limit the cost per invocation of the Lambda functions.
To minimize the cold start times of Lambda functions, we ran them outside of a VPC because of the way ENIs interact with Lambda and a VPC. Currently this is a known problem by AWS – Lambda has to wait for the NIC to be attached in the VPC, up to 10 seconds – they are re-working this. Once AWS have a solution for that, there should be no downside to running Lambda functions inside a VPC.
Terraform is one of the resident tools at Skyscrapers. If we need to create and/or update infrastructure it’s always done through code. However with Lambda and serverless the Serverless framework quickly became the tool of choice. Both frameworks have more or less the same functionality, however both are built for different use cases. Together with the customer we concluded that when a developer does a code change he or she might not want to change things on the static or database components. Therefore we made a split: everything related to Lambda and the API Gateway gets configured with the Serverless framework and everything static gets configured in Terraform. By splitting those 2 up the risk of changing something unintended was reduced.
To glue everything together we made use of Concourse CI. In pipelines we automated all deployments of code and infrastructure. This enabled the customer to focus on development rather than sorting out how to deploy their code in a consistent and controlled way.
This process resulted in a newly designed application that is ready for the customer’s future needs. The frontend is hosted on S3 and Cloudfront and is 100% separated from the backend code that is running on Lambda. The persistence layer is future proof and the idle cost of the infrastructure is drastically reduced.

During this period the platform served 1.574.396 sessions with over 43 million pageviews with peaks to 25.000 concurrent users with an average page load time of 1.07 seconds.

We were able to reduce the total AWS bill from $4.636,41 (for similar campaigns) to $400,19 compared to the previous campaign (a 91% saving) while having an uptime of 100%.
Fun fact: notice how the actual compute cost of Lambda is combined in the category Other Services; The total cost for Lambda was only $2.05.
Want to find out if your workloads can benefit from moving to serverless? Contact us to find out!






